OpenR - An Open Source Framework for Advanced Reasoning with LLMs

![]()




![]()
![]()
Paper · Tutorial · Code · Docs · Data · Model · Issue
Get started now View it on GitHub
Table of contents
🚀 News and Updates
[11/10/2024] OpenR now supports MCTS reasoning ! (#24)
[11/10/2024] Our paper is on Arxiv !
[11/10/2024] OpenR has been released!
Key Features
- ✅ Process-supervision Data Release
- ✅ Online RL Training
- ✅ Generative and Discriminative PRM Training
- ✅ Multiple Search Strategies
- ✅ Test-time Computation
- ✅ Test-time Scaling Law
What is OpenR?
OpenR is an open-source framework that integrates search, reinforcement learning and process supervision to improve reasoning in Large Language Models.
OpenAI o1 has demonstrated that leveraging reinforcement learning to inherently integrate reasoning steps during inference can greatly improve a model’s reasoning abilities.
We attribute these enhanced reasoning capabilities to the integration of search, reinforcement learning, and process supervision, which collectively drive the development of OpenR.
Our work is the first to provide an open-source framework demonstrating how the effective utilization of these techniques enables LLMs to achieve advanced reasoning capabilities,
What Can OpenR Do?
We believe the ability of reasoning can be improved by the following:
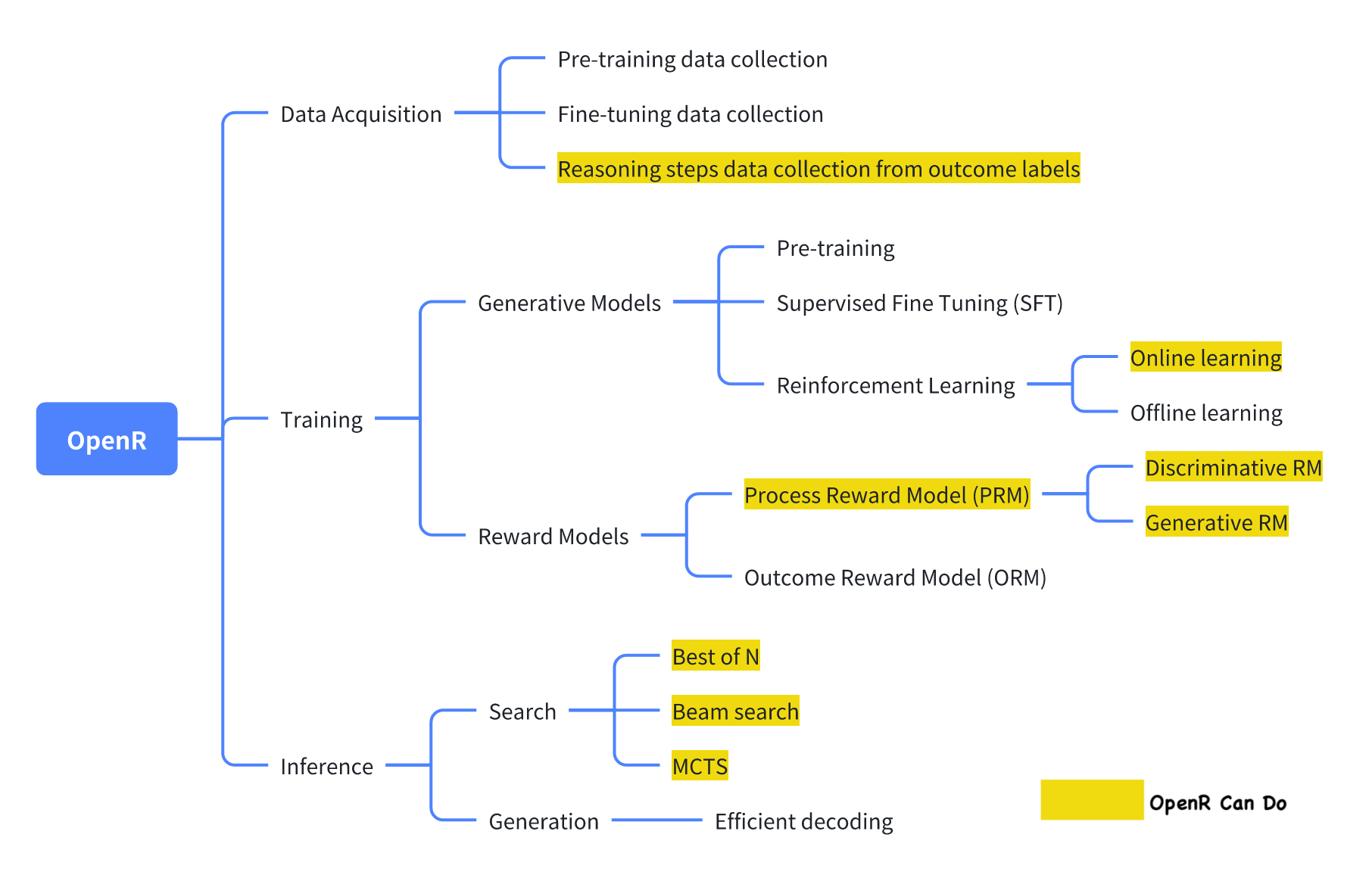
-
Data Acquisition: This pathway emphasizes the critical role of high-quality, diverse datasets in training LLMs. It includes data collection for both model pre-training and fine-tuning, with a specific focus on reasoning process, which are central to OpenR’s objectives. Given the significant costs associated with human annotation of reasoning data, we offer an automated pipeline that extracts reasoning steps from outcome labels, reducing manual effort while ensuring the collection of valuable reasoning information.
-
Training: This pathway centers around training strategies that enhance the reasoning capabilities of LLMs, from the perspective of both generative models and reward models. OpenR provide toolkits such as online reinforcement learning to train LLMs as the proposer, and methods to learn Process-supervision Reward Models (PRMs) as the verifier.
-
Inference: This pathway focuses on the scaling law at test-time, enabling LLM to give refined outputs through ways of generation or searching. OpenR allows us to select among various search algorithms—such as beam search, best-of-N selection, and others—each with unique advantages depending on the quality of the process reward models.
How to OpenR?
In the documentation, we provide some runnable code example as well as detailed usage of some key modules in the framework.
- Quick Start contains some ready-to-run code examples that can give you a head start on OpenR.
- Usage discuss details of key modules in the codebase.
- Datasets give you a sense of how we use data in our experiments.
To any interested in making OpenR better, there are still improvements that need to be done. We welcome any form of contribution and feel free to have a look at our contribution guidance.
Citing OpenR
To cite this project in publications:
@article{wang2024openr,
title={OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models},
author={Wang, Jun and Fang, Meng and Wan, Ziyu and Wen, Muning and Zhu, Jiachen and Liu, Anjie and Gong, Ziqin and Song, Yan and Chen, Lei and Ni, Lionel M and others},
journal={arXiv preprint arXiv:2410.09671},
year={2024}
}